» Download this section as PDF (opens in a new tab/window)
Nutanix AOS storage is the scale-out storage technology that appears to the hypervisor like any centralized storage array, however all of the I/Os are handled locally to provide the highest performance. More detail on how these nodes form a distributed system can be found in the next section.
Nutanix AOS storage is composed of the following high-level structure:
The following figure shows how these map between AOS and the hypervisor:
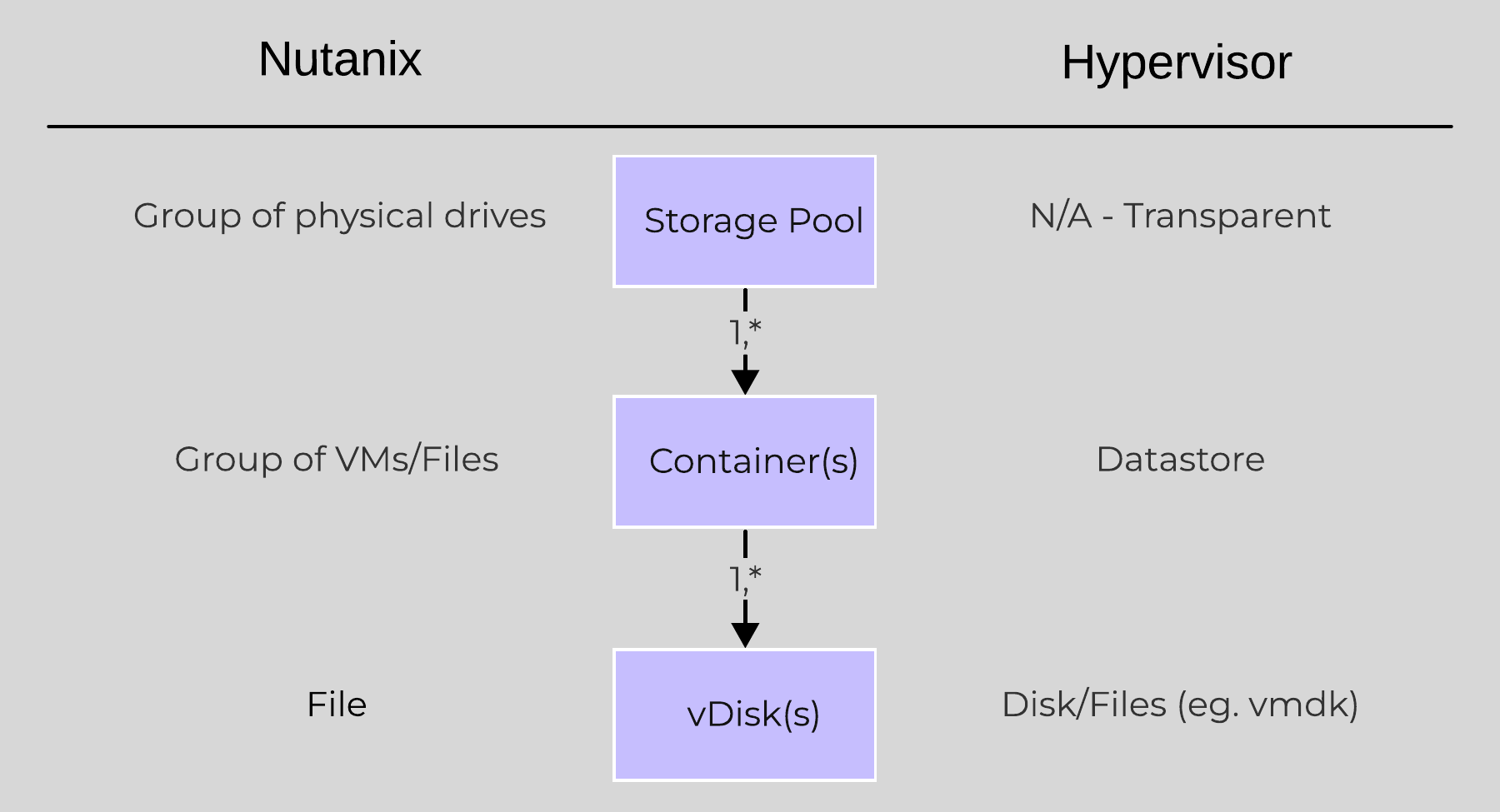 High-level Filesystem Breakdown
High-level Filesystem Breakdown
The following figure shows how these structs relate between the various file systems:
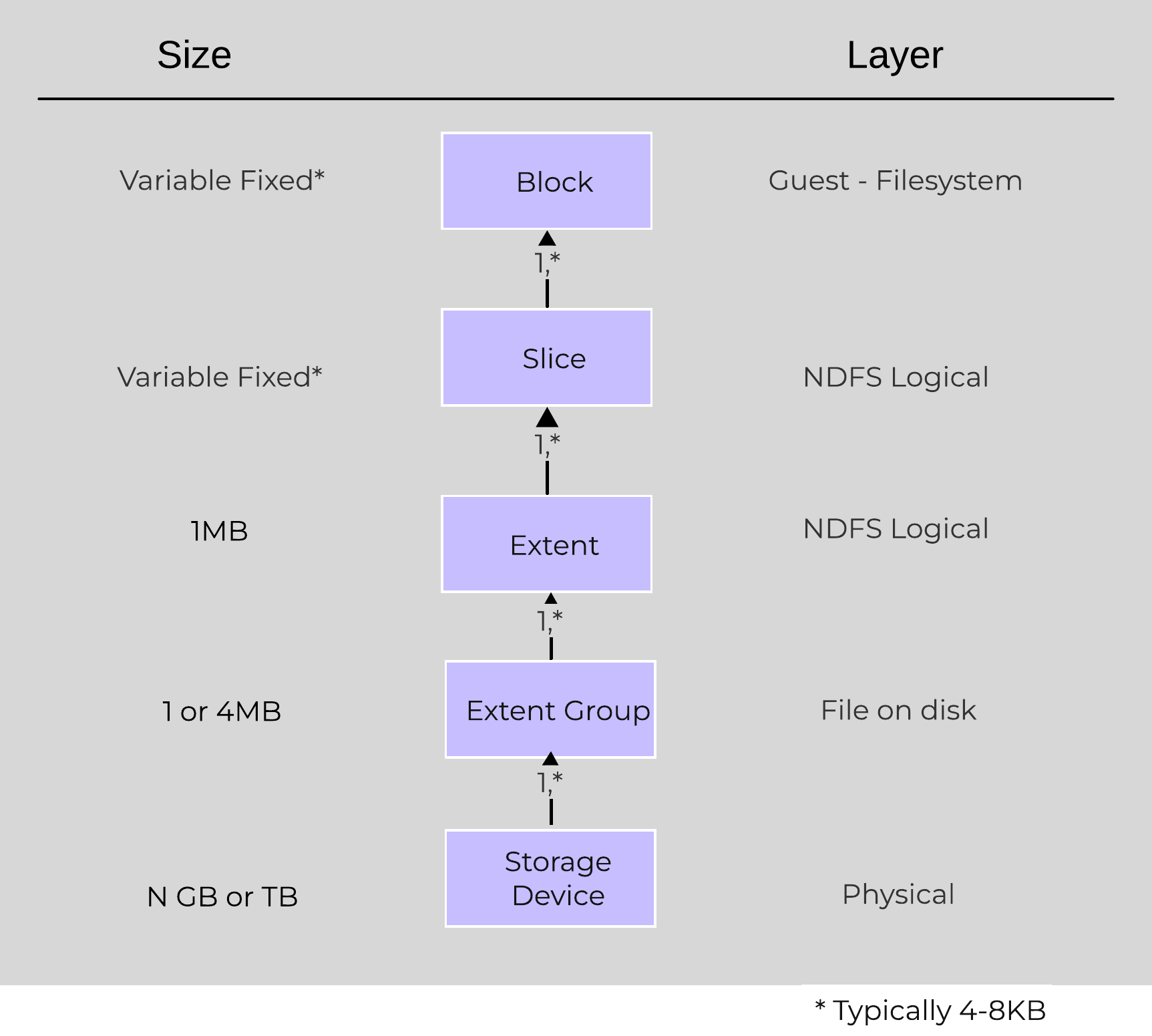 Low-level Filesystem Breakdown
Low-level Filesystem Breakdown
Here is another graphical representation of how these units are related:
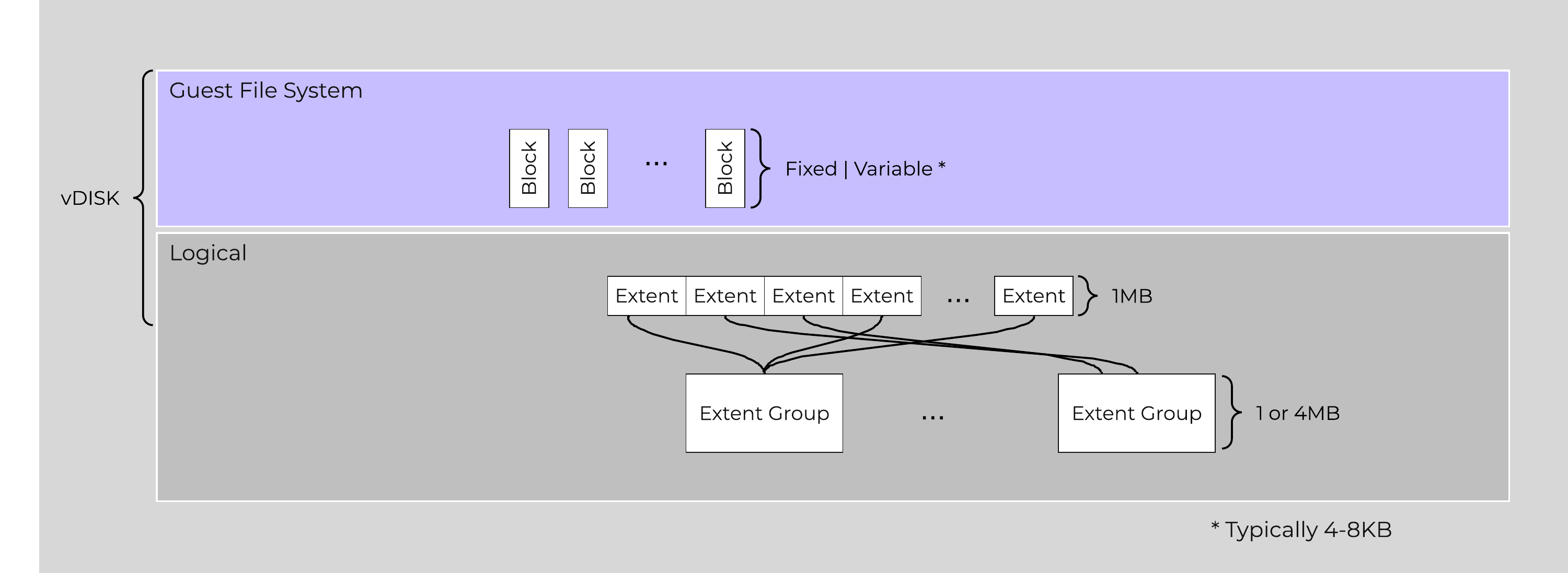 Graphical Filesystem Breakdown
Graphical Filesystem Breakdown
For a visual explanation, you can watch the following video: LINK
The typical hyperconverged storage I/O path can be characterized into the following core layers:
The following image shows a high-level overview of these layers:
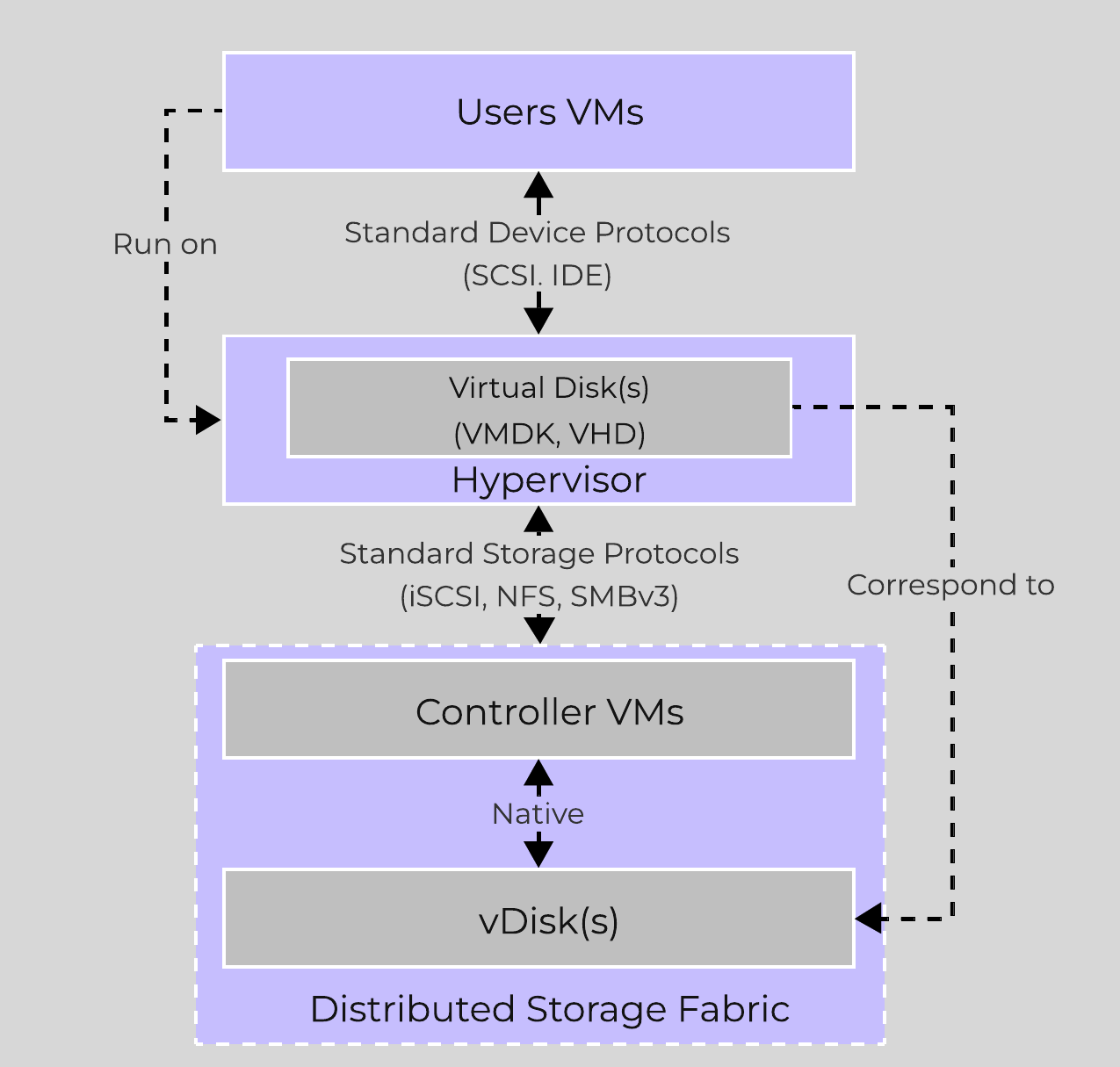 High-level I/O Path - Traditional
High-level I/O Path - Traditional
Within the CVM the Stargate process is responsible for handling all storage I/O requests and interaction with other CVMs / physical devices. Storage device controllers are passed through directly to the CVM so all storage I/O bypasses the hypervisor.
The following image shows a high-level overview of the traditional I/O path:
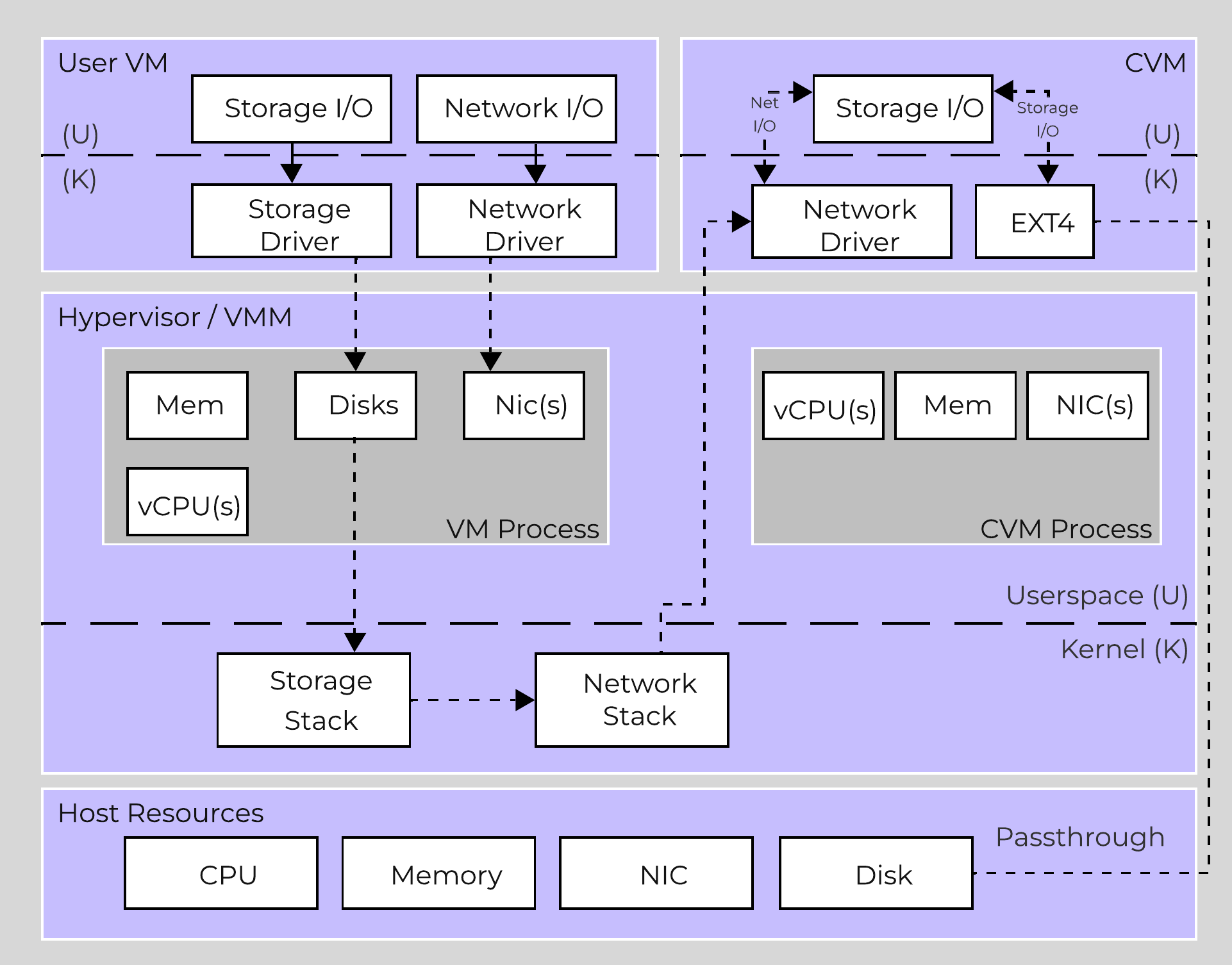 High-level I/O Path
High-level I/O Path
Nutanix BlockStore is an AOS capability which creates an extensible filesystem and block management layer all handled in user space. This eliminates the filesystem from the devices and removes the invoking of any filesystem kernel driver. The introduction of newer storage media (e.g. NVMe), devices now come with user space libraries to handle device I/O directly (e.g. SPDK) eliminating the need to make any system calls (context switches). With the combination of BlockStore + SPDK all Stargate device interaction has moved into user space eliminating any context switching or kernel driver invocation.
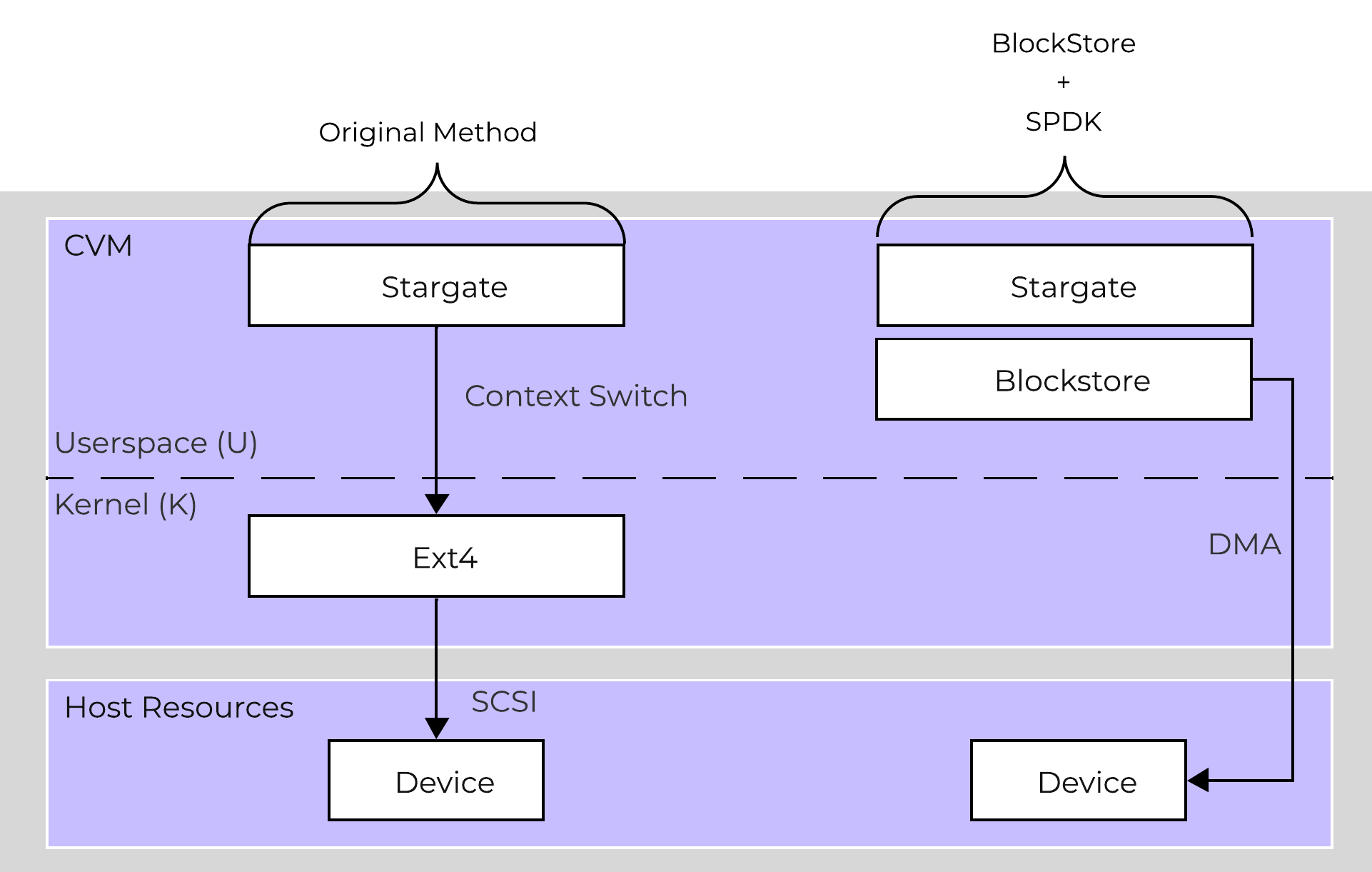 Stargate - Device I/O Path
Stargate - Device I/O Path
The following image shows a high-level overview of the updated I/O path with BlockStore + SPDK:
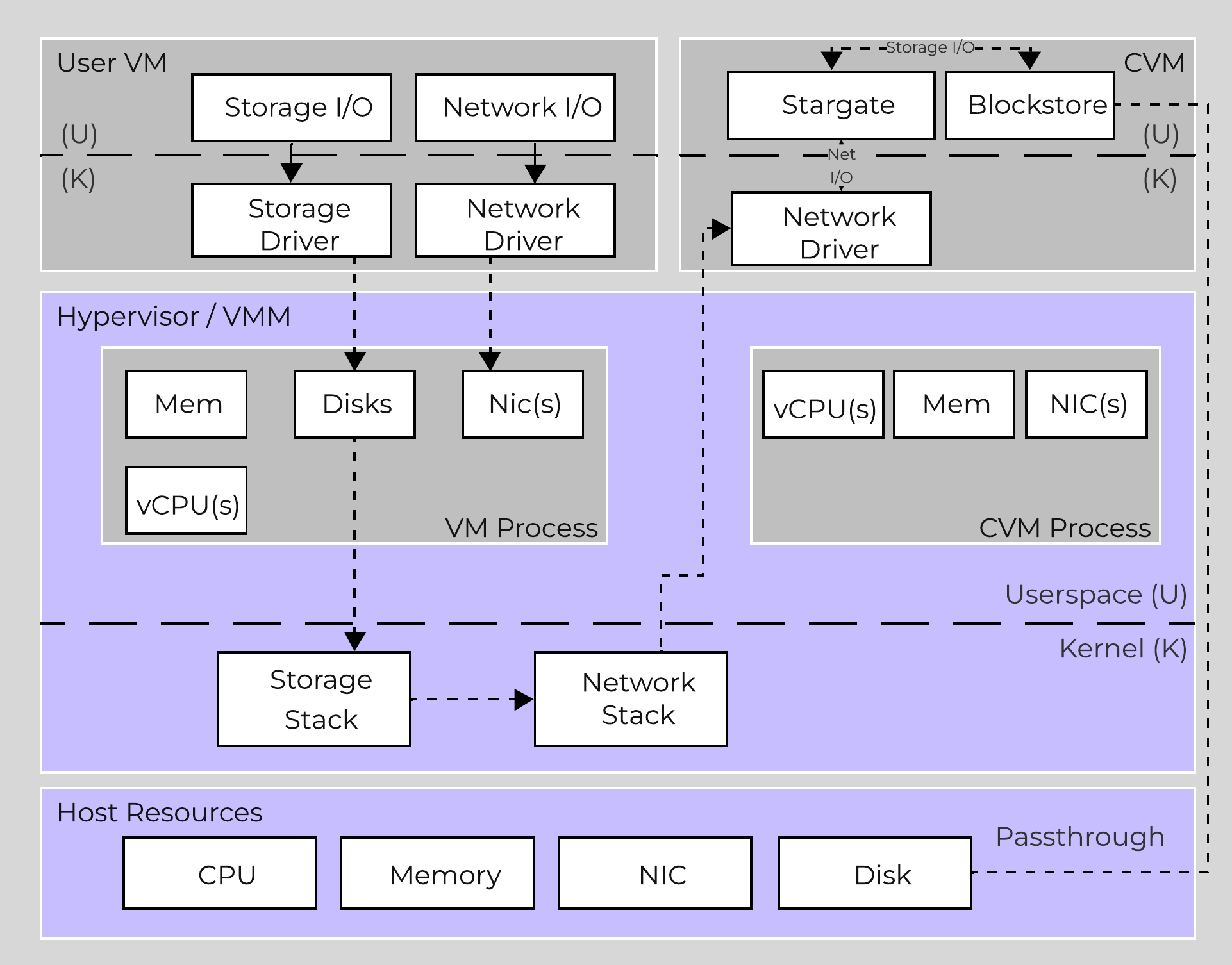 High-level I/O Path - BlockStore
High-level I/O Path - BlockStore
To perform data replication the CVMs communicate over the network. With the default stack this will invoke kernel level drivers to do so.
However, with RDMA these NICs are passed through to the CVM, bypassing the hypervisor and reducing interrupts. Also, within the CVM all network traffic using RDMA only uses a kernel level driver for the control path, then all actual data I/O is done in user-space without any context switches.
The following image shows a high-level overview of the I/O path with RDMA:
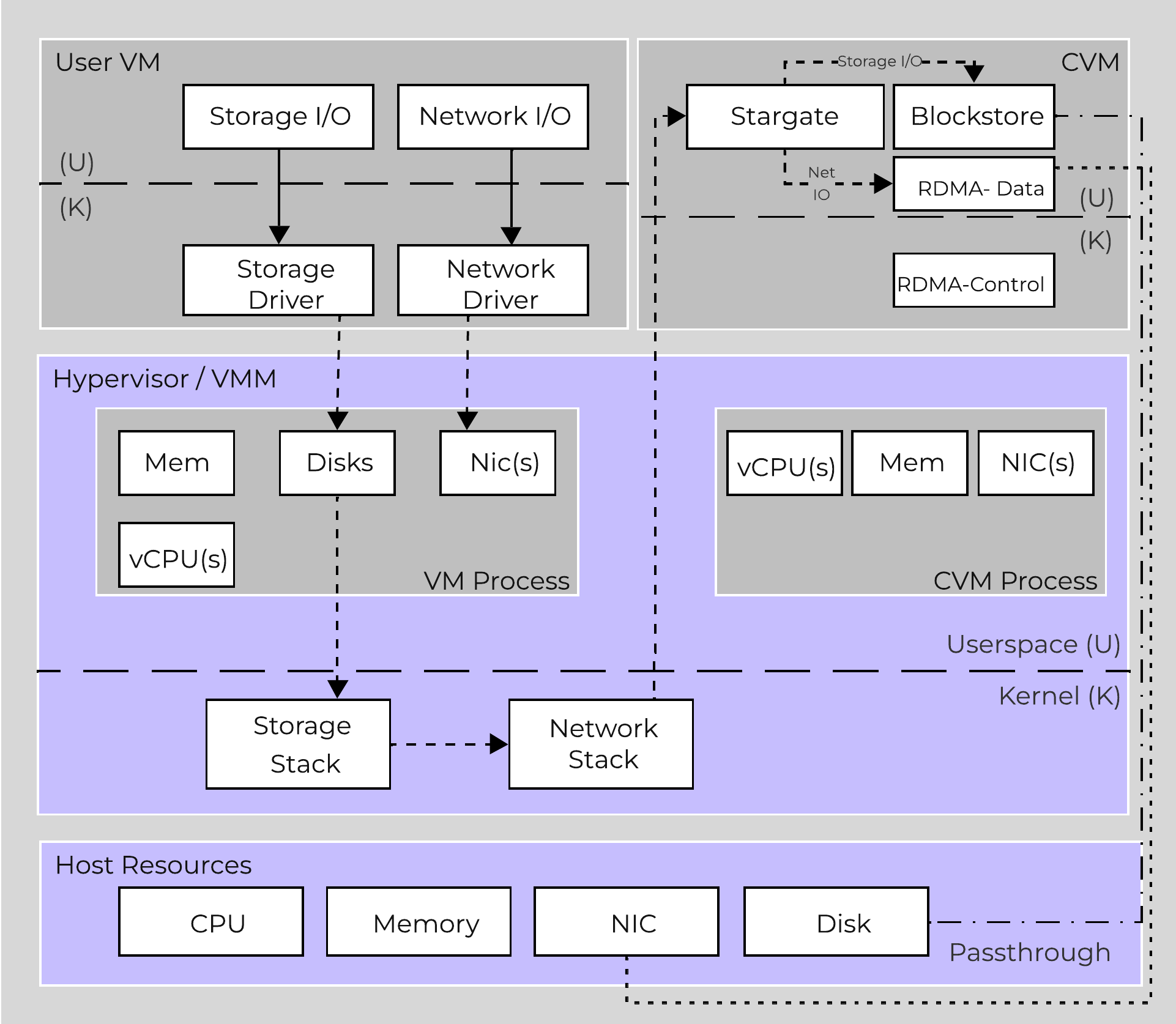 High-level I/O Path - RDMA
High-level I/O Path - RDMA
To summarize, the following enhancements optimize with the following:
Within the CVM the Stargate process is responsible for handling all I/O coming from user VMs (UVMs) and persistence (RF, etc.). When a write request comes to Stargate, there is a write characterizer which will determine if the write gets persisted to the OpLog for bursty random writes, or to Extent Store for sustained random and sequential writes. Read requests are satisfied from Oplog or Extent Store depending on where the data is residing when it is requested.
The Nutanix I/O path is composed of the following high-level components:
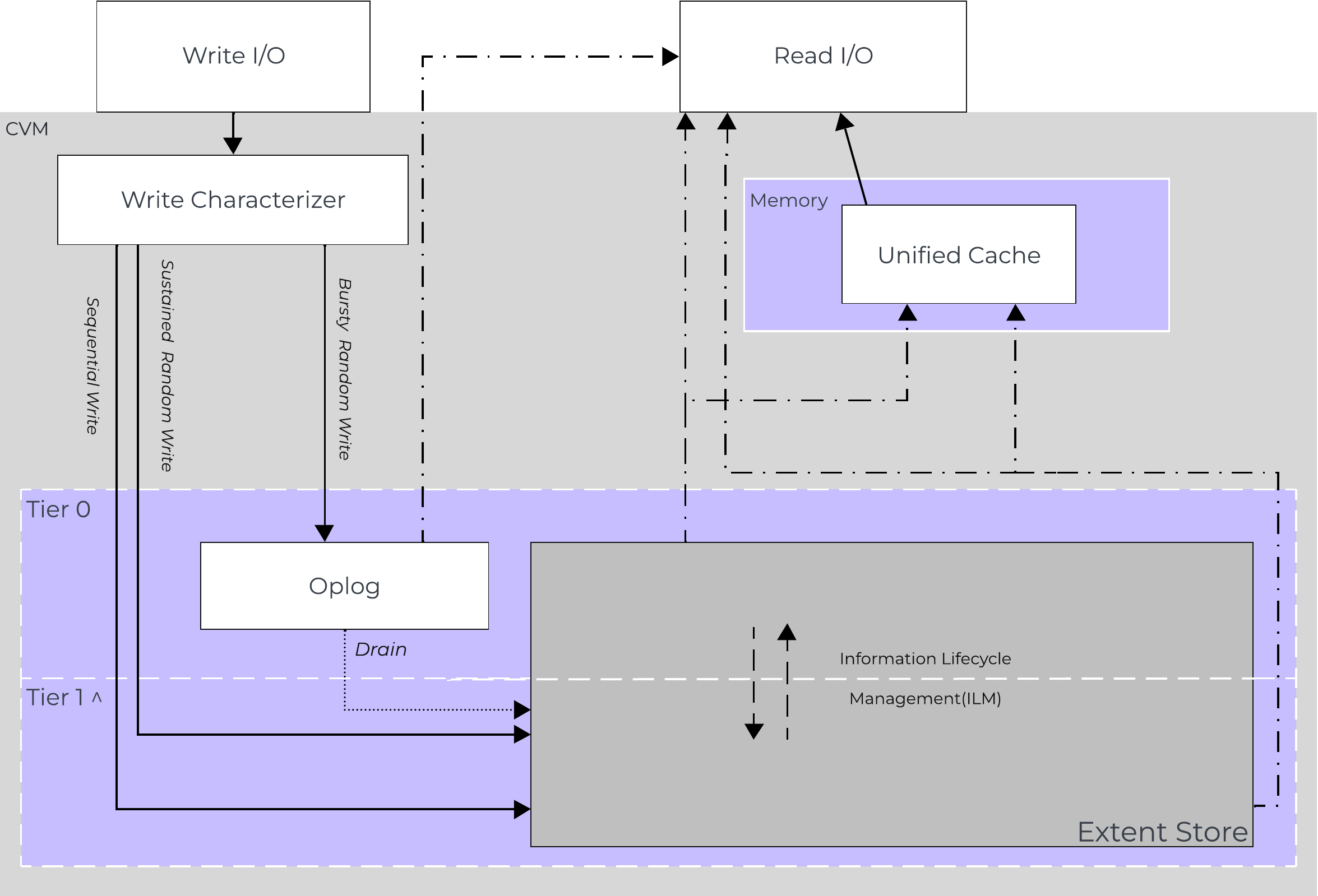 AOS I/O Path
AOS I/O Path
^:
Write IO is deemed as sequential when there is more than 1.5MB of outstanding write IO to a vDisk. IOs meeting this will bypass the OpLog and go directly to the Extent Store since they are already large chunks of aligned data and won't benefit from coalescing.
This is controlled by the following Gflag: vdisk_distributed_oplog_skip_min_outstanding_write_bytes.
All other IOs, including those which can be large (e.g. >64K) will still be handled by the OpLog.
Description: The Autonomous Extent Store (AES) is a method for writing / storing data in the Extent Store. It leverages a mix of primarily local + global metadata (more detail in the ‘Scalable Metadata’ section following) allowing for much more efficient sustained performance due to metadata locality. For sustained random write workloads, these will bypass the OpLog and be written directly to the Extent Store using AES. For bursty random workloads these will take the typical OpLog I/O path then drain to the Extent Store using AES where possible.
In AOS 6.8, an enhancement to AES was introduced called AES Optimized Metadata to improve performance and maximize resource utlization for all-flash and NVMe clusters. It was built to reduce CPU usage and drive the performance for sustained random writes going to the Extent Store. With AES Optimized Metadata, writes are batched into fewer transaction updates. This helps in reducing the number of disk operations needed to persist sustained random writes to the extent store. This translates to more optimized CPU usage through fewer cycles consumed and drives higher sustained random write performance on all-flash and NVME clusters.
The following figure shows a high-level overview of the Unified Cache:
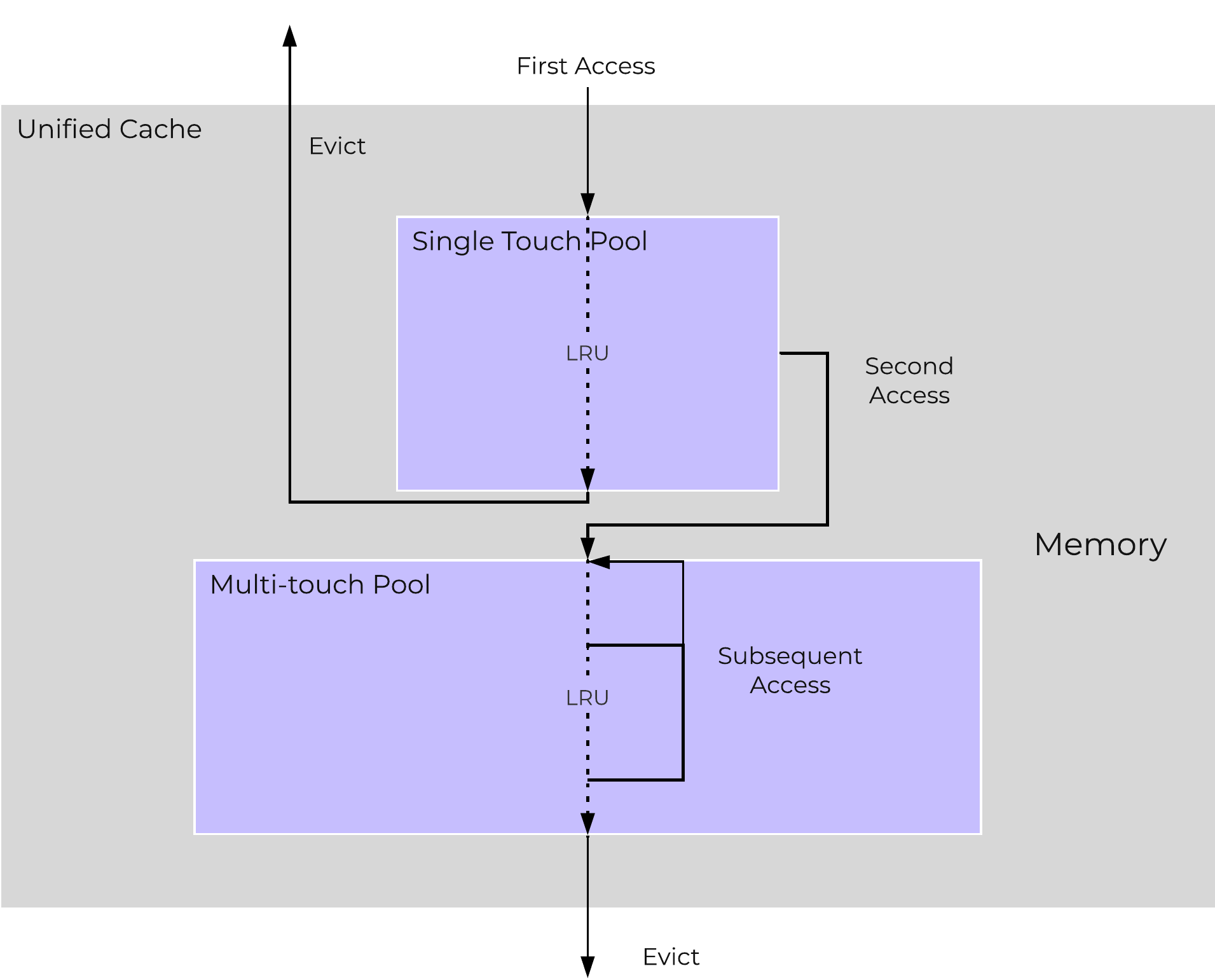 AOS Unified Cache
AOS Unified Cache
Data is brought into the cache at a 4K granularity and all caching is done real-time (e.g. no delay or batch process data to pull data into the cache).
Each CVM has its own local cache that it manages for the vDisk(s) it is hosting (e.g. VM(s) running on the same node). When a vDisk is cloned (e.g. new clones, snapshots, etc.) each new vDisk has its own block map and the original vDisk is marked as immutable. This allows us to ensure that each CVM can have it's own cached copy of the base vDisk with cache coherency.
In the event of an overwrite, that will be re-directed to a new extent in the VM's own block map. This ensures that there will not be any cache corruption.
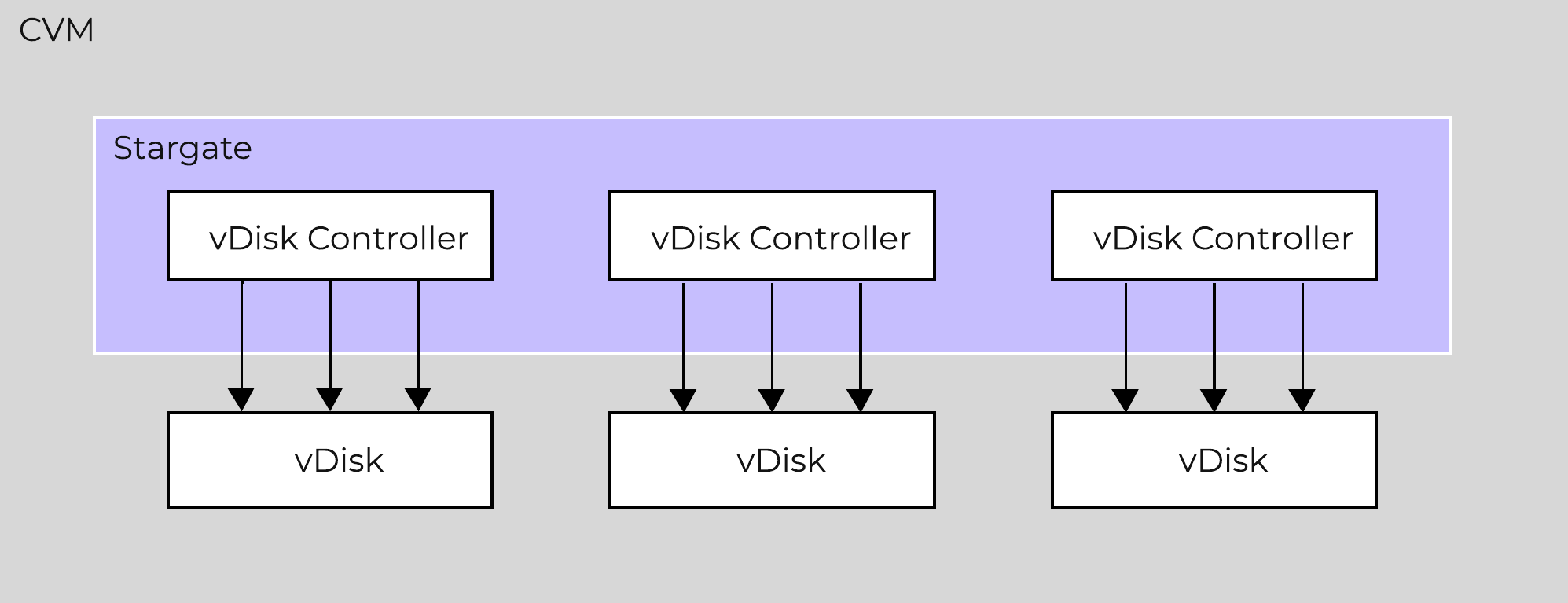
AOS was designed and architected to deliver performance for applications at scale. Inside Stargate, I/O is processed by threads for every vdisk created by something called vdisk controller. Every vdisk gets its own vdisk controller inside Stargate responsible for I/O for that vdisk. The expectation was that workloads and applications would have multiple vdisks each having its own vdisk controller thread capable of driving high performance the system is capable of delivering.
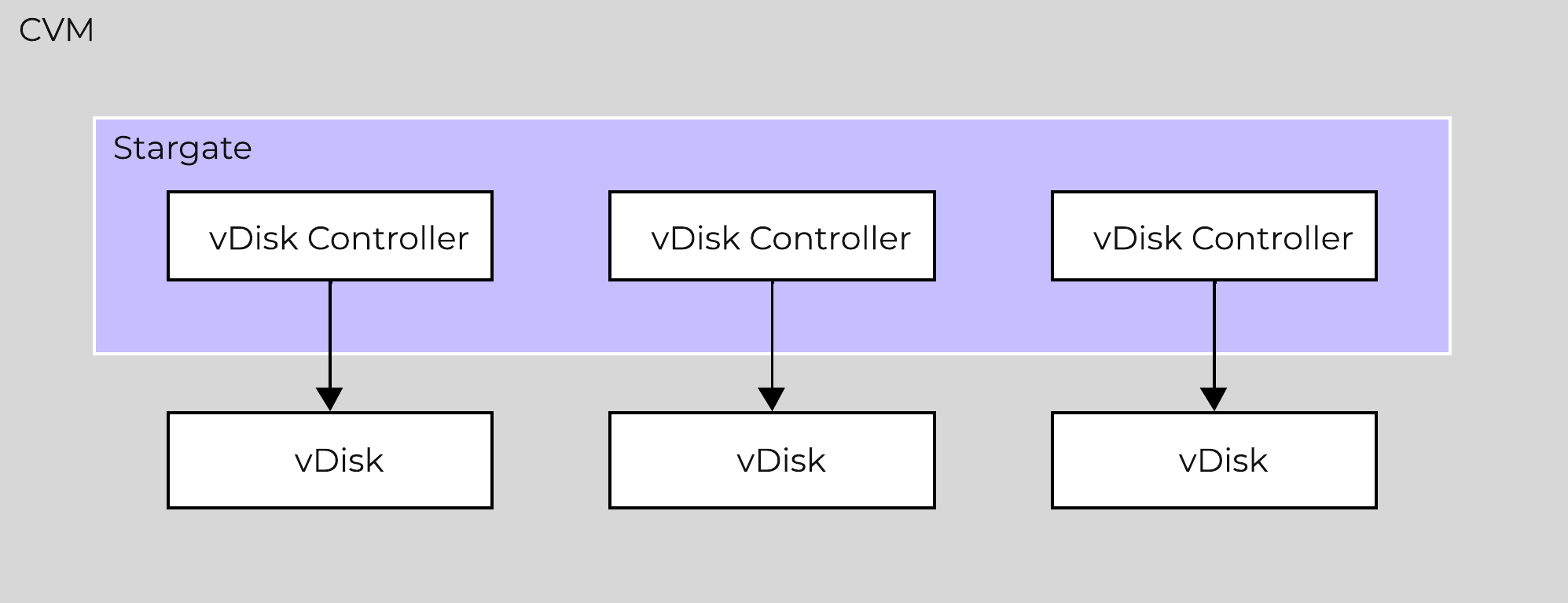
This architecture works well except in cases of traditional applications and workloads that had VMs with single large vdisk. These VMs were not able to leverage the capabilities of AOS to its fullest. So we enhanced our architecture such that the vdisk controller requests to a single vdisk are now distributed to multiple vdisk controllers. This is accomplished by creating shards of the controller, each having its own thread. I/O distribution to multiple controllers is done by a primary controller so for external interaction this still looks like a single vdisk. This results in effectively sharding the single vdisk making it multi-threaded. This enhancement alongwith other technologies talked above like Blockstore, AES allows AOS to deliver consistent high performance at scale even for traditional applications that use a single vdisk.
For a visual explanation, you can watch the following YouTube video: Tech TopX by Nutanix University: Scalable Metadata
Metadata is at the core of any intelligent system and is even more critical for any filesystem or storage array. For those unsure about the term ‘metadata’; essentially metadata is ‘data about data’. In terms of AOS, there are a few key principles that are critical for its success:
As of AOS 5.10 metadata is broken into two areas: global vs. local metadata (prior all metadata was global). The motivation for this is to optimize for “metadata locality” and limit the network traffic on the system for metadata lookups.
The basis for this change is that not all data needs to be global. For example, every CVM doesn’t need to know which physical disk a particular extent sits on, they just need to know which node holds that data, and only that node needs to know which disk has the data.
By doing this we can limit the amount of metadata stored by the system (eliminate metadata RF for local only data), and optimize for “metadata locality.”
The following image shows the differentiation between global vs. local metadata:
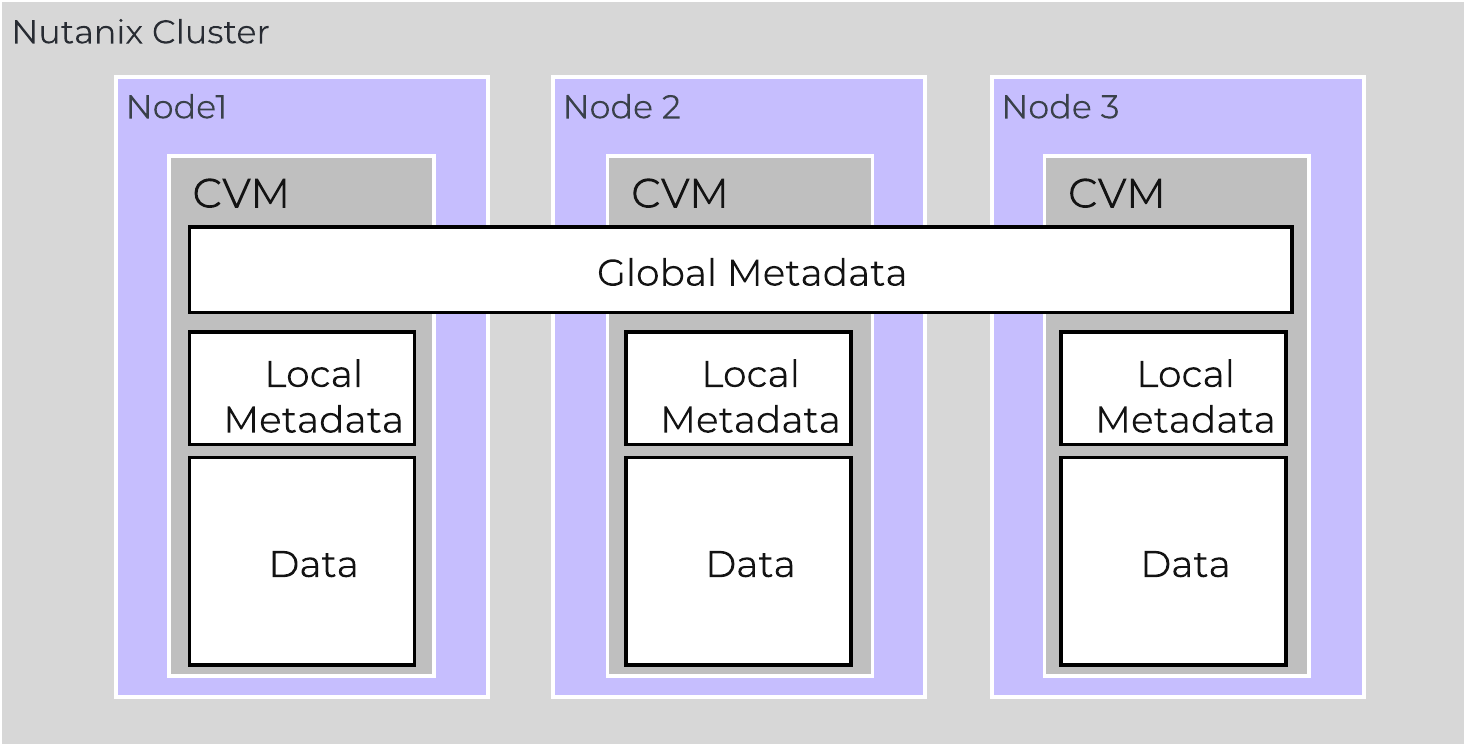 Global vs. Local Metadata
Global vs. Local Metadata
The section below covers how global metadata is managed:
As mentioned in the architecture section above, AOS utilizes a “ring-like” structure as a key-value store which stores essential global metadata as well as other platform data (e.g., stats, etc.). In order to ensure global metadata availability and redundancy a replication factor (RF) is utilized among an odd amount of nodes (e.g., 3, 5, etc.). Upon a global metadata write or update, the row is written to a node in the ring that owns that key and then replicated to n number of peers (where n is dependent on cluster size). A majority of nodes must agree before anything is committed, which is enforced using the Paxos algorithm. This ensures strict consistency for all data and global metadata stored as part of the platform.
The following figure shows an example of a global metadata insert/update for a 4 node cluster:
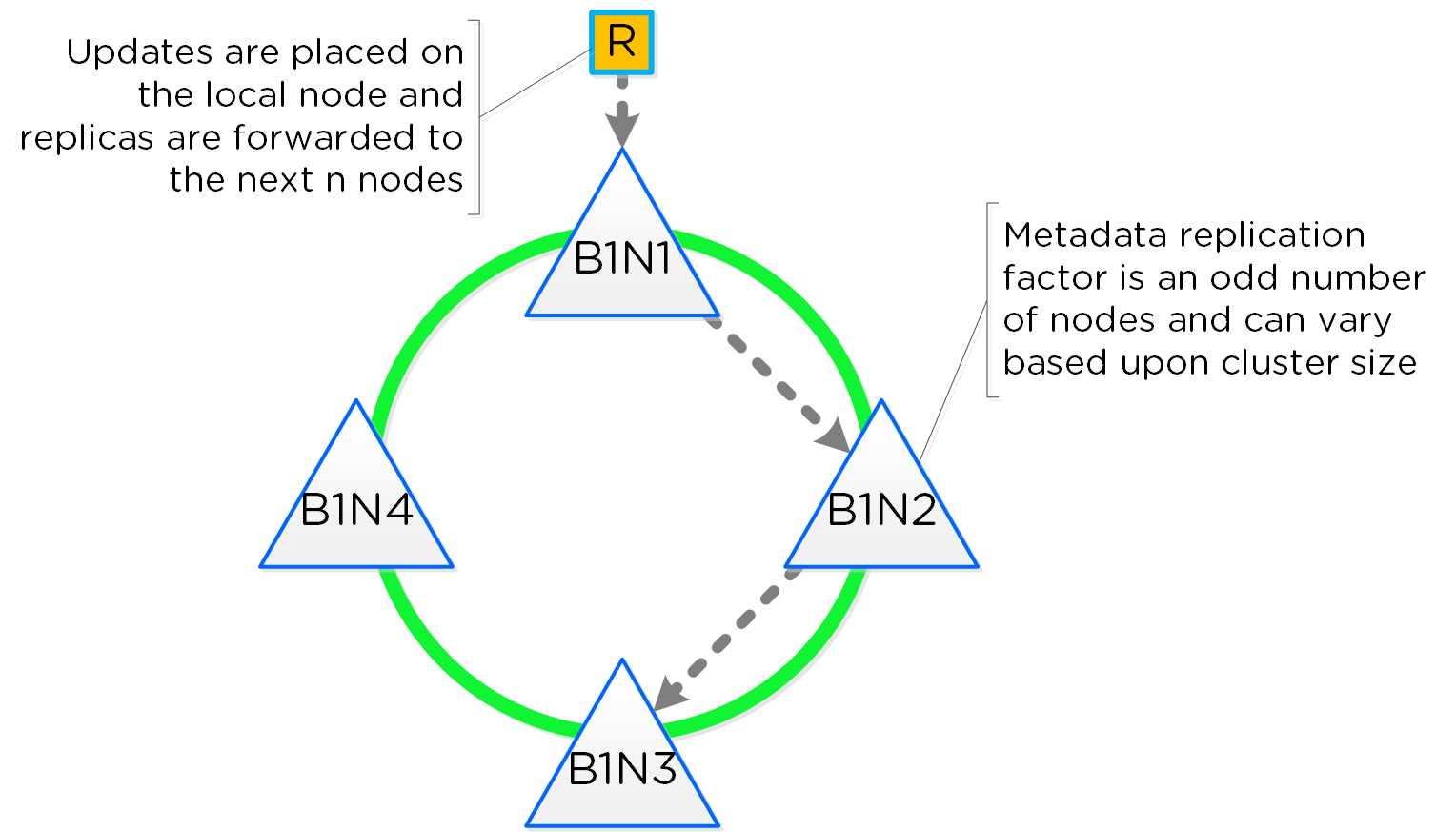 Cassandra Ring Structure
Cassandra Ring Structure
Performance at scale is also another important struct for AOS global metadata. Contrary to traditional dual-controller or “leader/worker” models, each Nutanix node is responsible for a subset of the overall platform’s metadata. This eliminates the traditional bottlenecks by allowing global metadata to be served and manipulated by all nodes in the cluster. A consistent hashing scheme is utilized for key partitioning to minimize the redistribution of keys during cluster size modifications (also known as “add/remove node”). When the cluster scales (e.g., from 4 to 8 nodes), the nodes are inserted throughout the ring between nodes for “block awareness” and reliability.
The following figure shows an example of the global metadata “ring” and how it scales:
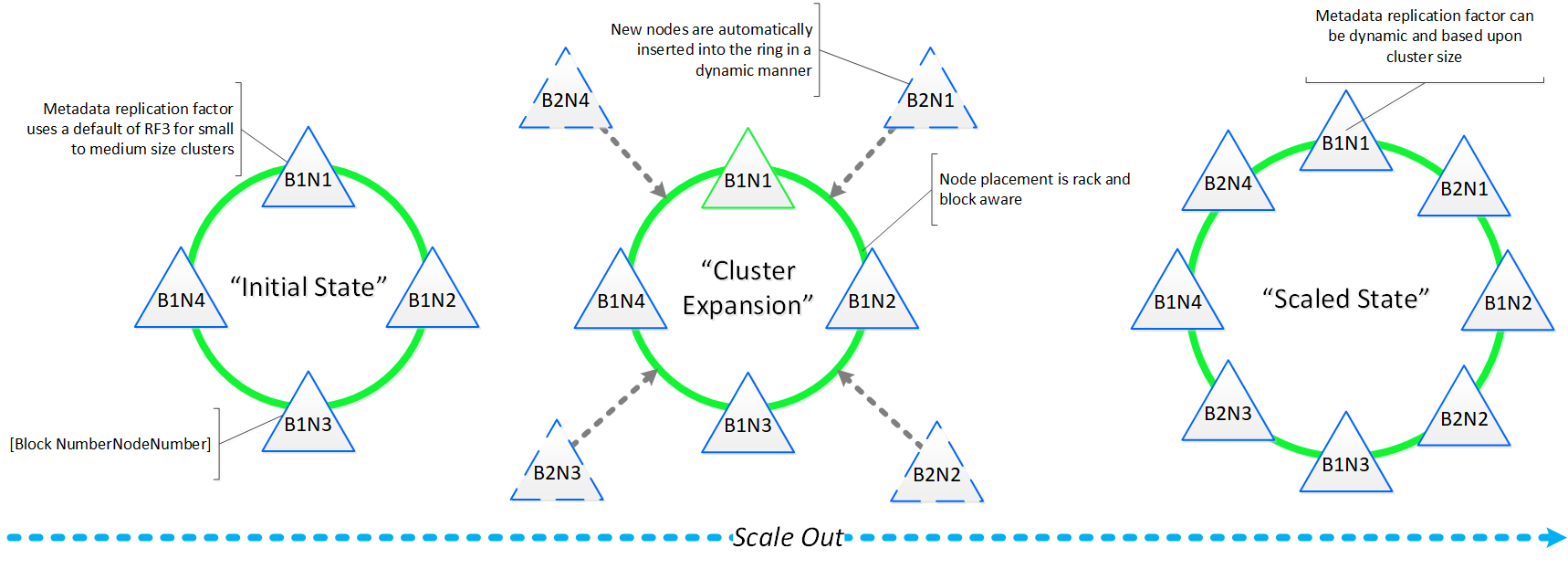 Cassandra Scale Out
Cassandra Scale Out
©2025 Nutanix, Inc. All rights reserved. Nutanix, the Nutanix logo and all Nutanix product and service names mentioned are registered trademarks or trademarks of Nutanix, Inc. in the United States and other countries. All other brand names mentioned are for identification purposes only and may be the trademarks of their respective holder(s).